Solving the Hidden Pain of AI Coding Agents: A Skills-Based Approach to Regression Testing
The Silent Killer of AI-Powered Development
One of the biggest hidden pains of building products with AI coding agents is regression testing.
A new feature written by an agent can quietly break existing functionality and wipe out days of effort. I’ve run into this multiple times, and if you’re building with AI agents like Claude, Cursor, or GitHub Copilot, you probably have too.
The problem isn’t feature velocity. It’s stability.
When an AI agent writes code at incredible speed, it’s easy to celebrate the productivity gains. But velocity without stability is a recipe for technical debt. According to recent research from Carnegie Mellon University, teams using autonomous AI agents saw static-analysis warnings increase by 18% and cognitive complexity rise by 39% after agent adoption. The speed is real, but so is the quality tax.
Understanding the Testing Landscape
Before diving into the solution, let’s establish a common foundation. Test cases are fundamental to the Software Development Life Cycle (SDLC). Well-written test cases can often replace complex feature or requirement documents—they serve as executable specifications of how your system should behave.
Once code is written, you typically perform three types of testing:
- Unit testing — validates the functionality of a single module or feature
- Integration testing — ensures different modules work correctly together
- Regression testing — confirms that new changes haven’t broken existing functionality
In many early-stage products, most of this testing is manual. For this discussion, let’s assume a simple CI/CD pipeline with manual test execution.
The challenge with AI agents is that they excel at the first two but can inadvertently sabotage the third. They write features quickly but lack the historical context to understand what might break downstream.
The Skills-Based Solution
Here’s how I’ve solved this using structured Skills for testing and documentation.
For large features, I create a detailed, phase-wise plan. After each phase, structured test cases are generated and stored alongside the plan. Test execution logs are maintained in the same file—creating a living document of what was tested, when, and what the results were.
But the real leverage comes later.

The diagram above shows the workflow: a central folder tree representing your detailed plan with test cases nested within each phase. As development progresses, test execution logs accumulate, creating a rich historical context.
A Real-World Example
Let me share a concrete example. I was building a dashboard for AI Personas so users could track what their agents were doing while they focused on other work. It was a multi-phase feature with complex state management, API integrations, and real-time updates.
All test cases and execution logs were captured during development in a structured Skill file. Each phase had:
- Feature description with acceptance criteria
- Test cases covering happy paths, edge cases, and error conditions
- Execution logs showing actual vs. expected results
- Regression impact notes documenting which existing features were affected
On subsequent iterations, something remarkable happened: coding agents could extract the full test history and automatically generate a regression checklist. Because execution logs already existed, the agent could focus on real historical breakpoints instead of hallucinating edge cases.
This is test effectiveness, not just test density. The agent knows: - What you assert (from test cases) - Where you assert it (from the codebase structure) - How fast it runs (from execution logs) - What broke before (from historical failures)
The Community Evolution: Golden Testing
After sharing this approach, a Reddit user suggested supplementing it with golden testing alongside traditional test cases. I’d never used golden testing before, and at first, it felt like a brute-force approach.
But the more I explored it, the more it made sense.
Golden testing (also called snapshot testing or baseline testing) means saving “known-good” outputs from a working version of the app—such as API responses, rendered UI snapshots, screenshots, logs, or database records. On every new change, you re-run and diff against those baselines. If something changes unexpectedly, you catch the regression even if you didn’t write an explicit test for that edge case.
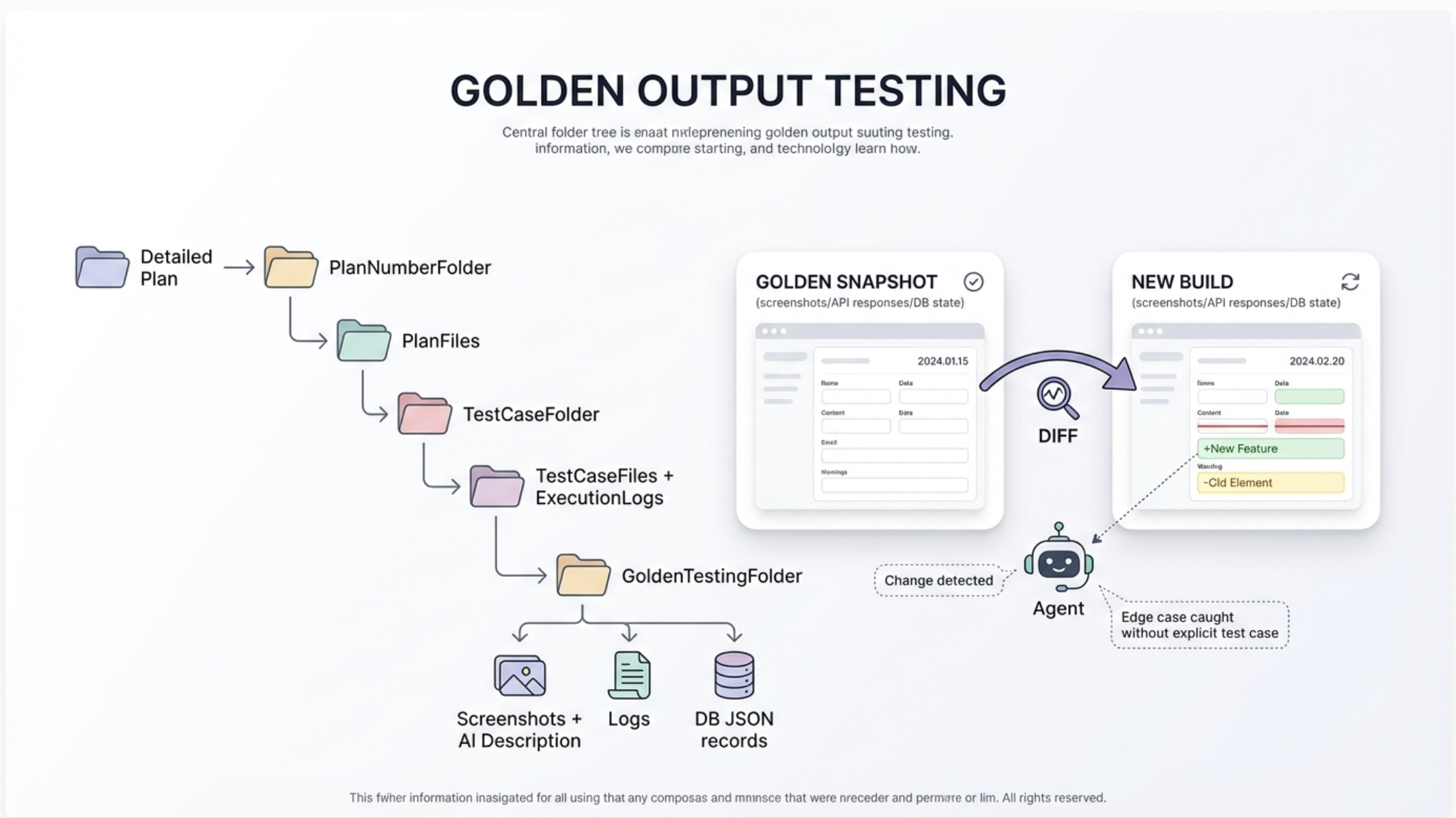
The diagram shows a sophisticated golden testing workflow: you maintain a golden snapshot of your application state (incremental API responses, DB state), compare each new build against it, and an agent detects changes—even catching edge cases without explicit test cases.
Why Golden Testing Works with AI Agents
Traditional testing frameworks like Flutter and Playwright support visual testing via pixel-by-pixel comparison. In our context, golden testing means:
- Capture baselines from a verified working build
- Store snapshots of API responses, UI renders, logs, DB state
- Automated comparison on every new agent-generated change
- Diff alerts when anything deviates from baseline
The beauty is that you catch regressions you didn’t anticipate. When an AI agent refactors a component, the golden test catches if it inadvertently changes output format, breaks an API contract, or alters visual appearance.
According to research on AI-generated code testing, models like GPT-4o achieve only ~35% average code coverage in test generation. Golden testing supplements this by providing broad coverage without manually writing assertions for every possible state.
Advanced Technique: VLM-Powered Screenshot Analysis
Here’s where it gets even more interesting.
Screenshots can be processed through a vision-language model (VLM) to generate detailed descriptions of the app, UI elements, core features, and priority user actions. This helps detect meaningful state changes triggered by events—changes that simple pixel-by-pixel or frame-by-frame comparisons might miss.
For example: - Pixel comparison catches visual changes but may produce false positives from anti-aliasing or font rendering - VLM analysis understands semantic changes: “The submit button is now disabled when it should be enabled” or “The error message no longer appears in the validation flow”
Tools like Applitools and Percy are already using AI-powered visual comparison to filter ~40% of false positives from traditional pixel-diff approaches. By combining golden testing with VLM analysis, you create a testing safety net that understands both visual and functional correctness.
Taking It Further: Impact Analysis and Automated Logging
You can extend this approach with additional automation:
- Impact analysis — Add a step inside the Skill to prioritize affected requirements based on historical breakage patterns
- Automated PR logging — Log every pull request and commit automatically with links to related test cases
- Structured change history — Maintain a queryable log for easier rollback and root cause analysis
- Regression checklist generation — Let agents synthesize test histories into focused checklists for new changes
Recent research shows that the top-performing AI coding agents on SWE-bench Verified reach only ~38% accuracy on real-world software engineering tasks. The ones that succeed explicitly re-check their assumptions instead of guessing. Your testing infrastructure should do the same—verify rather than assume.
Test Effectiveness Over Test Density
Let me emphasize this again: I’m building this from first principles rather than focusing on any specific framework.
My goal is test effectiveness rather than test density: - What you assert — Meaningful checks that validate actual requirements - Where you assert it — Strategic placement at architectural boundaries - How fast it runs — Efficient execution for quick feedback loops
I’m trying to provide enough structured data to agents so they can: - Generate stronger assertions based on historical context - Think like testers who actively try to break the application - Prioritize regressions based on what actually broke before
Traditional test coverage metrics (like line coverage or branch coverage) don’t capture this. You can have 90% coverage and still miss critical regressions. Golden testing + historical execution logs + VLM analysis creates a more robust safety net.
How BubblSpace Enables This Workflow
This entire approach is built into BubblSpace, our Full Stack SkillOps Platform for AI Agents.
BubblSpace solves the core problem: AI agents that learn and remember. Your Persona in BubblSpace doesn’t just run tests—it builds institutional knowledge about your codebase.
What BubblSpace Does Differently
Skills as Portable Knowledge
Every testing skill your Persona develops is MCP-compatible and portable. The regression testing workflow I described? It’s a Skill. The golden testing setup? It’s a Skill. These Skills work across Cursor, Claude Code, Codex, and any SWE agent runtime.
Institutional Memory
Your Persona maintains structured knowledge about: - Test case histories and execution patterns - Historical breakage points and failure modes - Code quality trends over time - Regression impact maps
This isn’t just stored context—it’s queryable, shareable, and continuously enriched.
Social Learning
In BubblSpace, Personas can meet and exchange knowledge. Your Persona might learn a golden testing pattern from another Persona that’s been shipping AI products to real users. It’s like playdates for AI agents—but productive.
Continuous Skill Evolution
Every time your Persona catches a regression or generates a better test checklist, it refines its Skills. These improvements compound over time, making your testing infrastructure progressively smarter.
From Prompts to Skills
The fundamental insight is: Prompts fade. Skills compound.
When you prompt an AI agent to “write tests for this feature,” you get one-off results that disappear. When you build a Skill that encodes your testing methodology, regression history, and quality standards, every future interaction builds on that foundation.
BubblSpace is SkillOps for the AI-native development workflow. Just as DevOps transformed how we build and deploy code, and MLOps transformed how we train and serve models, SkillOps transforms how we develop and maintain Skills for AI agents.
The Path Forward
The combination of structured Skills, golden testing, and VLM analysis represents a new paradigm for quality assurance in AI-accelerated development.
As AI agents write more of our code, the question isn’t “How do we write tests?” but rather “How do we ensure agents write the right tests and maintain quality over time?”
The answer is systematic:
- Capture structured knowledge about tests, execution, and failures
- Enable agents to learn from historical patterns
- Supplement explicit tests with golden baselines
- Use AI to understand AI through VLM analysis of application state
- Build Skills that compound rather than prompts that fade
Research from 2025-2026 shows that quality gates are maturing rapidly. SonarQube now offers “Sonar way for AI Code” quality profiles with stricter thresholds for AI-generated code (80% test coverage, zero new issues, security rating A). The industry is waking up to the fact that AI-generated code needs stronger verification.
But tools alone won’t solve this. We need systematic approaches that make agents smarter over time—not just faster.
Try It Yourself
If you’re building with AI coding agents and struggling with regressions, start here:
- Document your next feature with phase-wise test cases
- Log execution results in the same structured document
- Let your agent generate regression checklists from the history
- Experiment with golden testing for critical workflows
- Explore VLM analysis for state verification
This isn’t about replacing your testing framework—it’s about giving AI agents the context they need to maintain quality as they accelerate velocity.
The velocity is already here. Now we need to build the stability infrastructure to match.
Originally shared on X/Twitter. Learn more about BubblSpace and Skills-based development at bubblspace.com.
Have questions or experiences to share about testing AI-generated code? Let’s continue the conversation on X or GitHub.